An introduction to SIMD and ISPC in Rust
We don't use our hardware effectively
Single instruction, multiple data (SIMD) instructions allow for your CPU to operate on multiple elements of data per cycle. SIMD isn't easy but it is endlessly fascinating. There's an odd sense of joy gained from peering high level to low through the lens of the compiler, raw assembly, and the CPU those instructions are run on. It's the perfect knife edge between awe and expletives.
Thanks to autovectorization compilers can give you many of the benefits of SIMD with little work. Sadly that's not guaranteed. As noted by Lucas Meijer discussing the dangers of relying on autovectorization by the compiler:
I should be able to say “if this loop for some reason doesn’t vectorize, that should be a compiler error, not a ‘oh code is now just 8x slower but it still produces correct values, no biggy!’”
A tiny change in your code can destroy autovectorization with zero warning. We'll see below that tiny inefficiencies in your code can steal an enormous amount of performance. We'll also see tools that you can use to pick up on these issues that are far more detailed than timing an execution.
No matter how smart compilers get they'll likely never be able to perfectly optimize complex cases. Many times such optimizations require rethinking and recomposing the problem itself, not just tweaking a few lines of code.
Leaving those cases unoptimized can be tragic. Examples exist of stupendous speedups across a variety of tasks. Fast compression, ripgrep, roaring bitmaps that sit at the base of nearly every search engine, parsing JSON, vectorized emulation of 16 32-bit VMs per AVX-512 thread, ... Our hardware is capable of so much more and we can unlock it.
If we're particularly smart we can decompose a large complex problem into a tiny one and only spend our time hand optimizing that minimal use case. An example of this is BLIS:
BLIS is a portable software framework for instantiating high-performance BLAS-like dense linear algebra libraries. The framework was designed to isolate essential kernels of computation that, when optimized, immediately enable optimized implementations of most of its commonly used and computationally intensive operations.
Separate to all this it's still worth our time to investigate what's happening under the covers - even if theoretically we're cursed to be forever beaten by the compiler.
At worst you'll come away with a better understanding of how we're standing on the shoulders of giants. At best you may realize the giants were asleep this whole time and that standing on their shoulders works best when they're standing themselves.
In this post we'll use a simple example to pull apart some of the complexities and possibilities of SIMD. Not all details will be explored but it should provide a basis to delve into areas of interest. The code is available on GitHub though annotated below.
Task: pseudo dot product
The dot product between two vectors is z[i] = x[i] * y[i], or \(z_i = \sum_i x_i y_i \) if you prefer the mathematical notation.
We'll be performing a pseudo dot product, specifically z[i] += x[i] * y[i], for two reasons: first, the compiler is too smart and may remove our redundant loops as they're not used, and second, we want to demonstrate the fused multiply add (FMA) SIMD intrinsic.
I was also personally motivated to select the dot product as a task given it's a fundamental building block in many machine learning algorithms.
Aside: The compiler trying to be too smart can be the source of multiple issues. Certain compilers will see you zero memory for security purposes, realize you don't use the value again, and hence remove the memory zeroing as you're not "using" the zeroed memory.
Benchmark
For the benchmark we'll be performing a tight loop of pseudo dot products on 1024 dimensional f32 float vectors 10 million times. I'll be using an Intel Core i7-7700k CPU which supports various SIMD instruction sets up to and including AVX-2 instructions. The AVX-2 instruction set operates on 256 bits at a time - or in our case 8 f32 floats.
All code will be compiled and benchmarked using RUSTFLAGS="-C target-cpu=native", which essentially says "optimize for the CPU on this machine", and cargo run --release (release builds) to perform builds with full optimization.
For analyzing the resulting assembly we'll be using cargo asm, Linux's perf, and Intel's vTune.
For the final results we'll be using the average runtime determined by hyperfine, a command-line benchmarking tool available from Rust's Cargo.
Version 1: Naive Rust and naive C
Naive C:
void dotp(float *array1, float *array2, float *dest, size_t N) {
for (size_t i = 0; i < N; ++i) {
dest[i] += array1[i] * array2[i];
}
}
Naive Rust:
fn dotp(x: &[f32], y: &[f32], z: &mut [f32]) {
for ((a, b), c) in x.iter().zip(y.iter()).zip(z.iter_mut()) {
*c += a * b;
//*c = a.mul_add(*b, *c);
}
}
With Rust we have the option to use fused multiply add (FMA) to collapse vmulps (multiply) and vaddps (add) into a single instruction (vfmadd213ps) by using a.mul_add(b, c). This can improve performance as well as improve accuracy as the former uses one rounding operation per instruction compared to the latter that only uses one. This optimization is not the default in Rust for reproducibility reasons. In our case there is no substantial runtime difference in performance.
Results:
- Naive C: 809.9 ms ± 7.3 ms
- Naive Rust (
c += a * b): 890.4 ms ± 11.8 ms - Naive Rust (
mul_add): 894.2 ms ± 17.4 ms
Analysis using cargo asm
To understand why our code may be slow requires understanding how it becomes assembly. Whilst writing assembly can be unwieldy it's not too difficult to start reading it - at least when we get a bit of help.
cargo asm helps with this very issue. By interlacing your Rust code with the generated assembly we can see fairly clearly what is happening.
The command to produce the snippet below is RUSTFLAGS="-C target-cpu=native" cargo asm dotp::main --rust - specifically to generate the assembly for main in our program dotp.
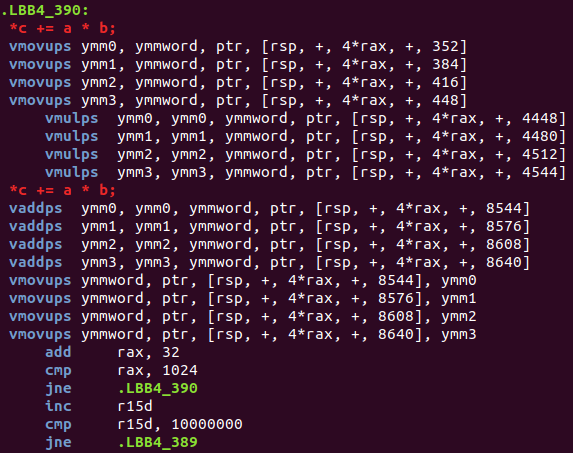
Here we can see that c += a * b is broken down into two parts:
- a load (
vmovupsor "Move Unaligned Packed Single-Precision Floating-Point Values") and a multiply featuring an implicit load (vmulps) - an add (
vaddps) with an implicit load and a save (vmovups)
From this we can see Rust has successfully autovectorized our code as it's using instructions that operate on multiple f32 elements simultaneously. The compiler has also decided to perform multiple of these instructions at a time, specifically
Analysis using perf
To see where our code may be having performance issues we can use Linux's perf command. In those mode we lose the interlaced Rust code but can see benchmarking that goes down to the instruction level.

Version 2: Rust SIMD intrinsics with and without inline
#[inline(never)]
fn simddotp(x: &[f32], y: &[f32], z: &mut [f32]) {
for ((a, b), c) in x
.chunks_exact(8)
.zip(y.chunks_exact(8))
.zip(z.chunks_exact_mut(8))
{
unsafe {
let x_a = _mm256_loadu_ps(a.as_ptr());
let y_a = _mm256_loadu_ps(b.as_ptr());
let r_a = _mm256_loadu_ps(c.as_ptr());
_mm256_storeu_ps(c.as_mut_ptr(), _mm256_fmadd_ps(x_a, y_a, r_a));
}
}
}
Here we step over our vector eight floats at a time (chunks_exact(8)) and use the load (_mm256_loadu_ps), fused multiply add (_mm256_fmadd_ps), and store (_mm256_storeu_ps) intrinsics. Note these are all unsafe instructions as we're dealing with pointers. If you're curious what a given SIMD instruction does you can look it up on Intel's Intrinsics Guide.
Now you may well wonder why we've disabled inlining with #[inline(never)]. If we allow inlining this is what we get for the assembly code output:

Note that, similar to the assembly from the naive Rust, all the instructions have been re-ordered. There are eight loads (vmovups) in a row, withe the vfmadd213ps (FMA) operations also including implicit loads, whereas the code we wrote above only performs three loads before performing the FMA operation.
Inlining allows for re-ordering of instructions as long as those instructions don't interfere with each other. In our case this appears to cause issues, likely stalls, as blocks of up to eight moves (vmovups) are scheduled in one go. With so many loads we don't take advantage of the ability to load and multiply at the same time. By turning off inlining we're able to prevent that and the given instructions (move, move, mul + move, save) are instead unrolled four times.
With inlining disabled we instead have:

which exactly matches the ordering of our hand written SIMD instructions. This allows for better utilization of all of the CPU rather than making the CPU stall all work whilst waiting on loads.
Aside: Rust may prevent certain code from being inlined if it contains SIMD intrinsics as those SIMD intrinsics might not be supported for all the hardware the binary is intended for.
Results:
- Naive C: 809.9 ms ± 7.3 ms
- Naive Rust (
c += a * b): 890.4 ms ± 11.8 ms - Naive Rust (
mul_add): 894.2 ms ± 17.4 ms - Rust SIMD (inline allowed): 887.4 ms ± 7.5 ms
- Rust SIMD (never inline): 734.4 ms ± 13.6 ms
Version 3: Rust-ISPC and Rust without bounds checking
What is ISPC?
The Intel Implicit SPMD Program Compiler (ISPC) is a compiler for a variant of the C programming language highly optimized for SIMD CPU architectures. Programs appear far closer to shaders or GPU code (OpenCL / CUDA) than traditional C. The restrictions and additional typing hints in the language allow for far more effective SIMD utilization than standard unconstrained C. ISPC also has a variety of features to simplify common SIMD tasks.
ISPC is BSD licensed and can target multiple different SIMD instruction sets from various hardware manufacturers (including AMD and Arm) without requiring a programmer. That's different to manually writing SIMD instructions, such as we've done above, as we would need to do so for each different instruction set (i.e. SSE, AVX-2, AVX-512, NEON, ...). This portability is why ISPC is now in Fortnite and Unreal Engine.
If you're interested in a swashbuckling story of how ISPC was created I strongly recommend reading The story of ISPC memoir, a multi-part series about how the compiler came to be from the guts of Intel.
If you squint the code is essentially the C we wrote above. When deviating those changes are pulled almost directly from suggestions in the ISPC Performance Guide .
export void dotp(uniform const float X[], uniform const float Y[], uniform float Z[]) {
foreach(i = 0 ... 1024) {
Z[i] += X[i] * Y[i];
}
}
You might think that adding another compiler to the project would be a massive headache but luckily the rust-ispc crate comes to our rescue. The library is even split into two crates - a compile and runtime crate - such that an end user won't need ISPC if they aren't modifying the ISPC code. The ispc-rust crate handles compilation, generating bindings, and linking all for you with only a half dozen lines of code.

In analyzing the resulting SIMD assembly from ISPC it's similar to our SIMD instructions above. One of the advantages that ISPC has is knowing the exact length of the vector - 1024 - and being able to optimize specifically for that. We can see that in the jump command at the end which keeps jumping if a variable is below (jb) 992 (0x3e0), adding 32 (0x20) each time before the check. Conveniently 992 + 32 = 1024.
For Rust, to remove the bounds checking:
#[inline(never)]
fn simddotp_no_bounds(x: &[f32], y: &[f32], z: &mut [f32]) {
for idx in 0..1024 / 8 {
unsafe {
let (a, b, c) = (
x.get_unchecked(idx * 8),
y.get_unchecked(idx * 8),
z.get_unchecked_mut(idx * 8),
);
let x_a = _mm256_loadu_ps(a);
let y_a = _mm256_loadu_ps(b);
let r_a = _mm256_loadu_ps(c);
_mm256_storeu_ps(c, _mm256_fmadd_ps(x_a, y_a, r_a));
}
}
}
The Rust code above can now assume we'll always be receiving vectors of length 1024 slightly different assembly to the previous Rust version. This is thanks to a for loop instead of iterators and avoiding bounds checking with get_unchecked.

Final tally
- Naive C: 809.9 ms ± 7.3 ms
- Naive Rust (
c += a * b): 890.4 ms ± 11.8 ms - Naive Rust (
mul_add): 894.2 ms ± 17.4 ms - Rust SIMD (inline allowed): 887.4 ms ± 7.5 ms
- Rust SIMD (never inline): 734.4 ms ± 13.6 ms
- Rust SIMD (never inline + unrolled): 728.2 ms ± 17.7 ms
- Rust ISPC: 642.9 ms ± 62.3 ms
The most surprising result is in the difference between the fastest Rust SIMD and the Rust ISPC. Both share highly similar resulting assembly and yet unknown minor differences enable the ISPC version to perform far better.
Analysis using Intel vTune

Intel's vTune is able to get access to hardware level profiling in order to see exactly what your CPU is up to, assuming you're running Intel hardware. Both the command line tool and the graphical tool will provide explicit advice when certain problematic code behaviours are seen.

Intel's vTune confirms that the ISPC generated code is faster than the Rust SIMD code due to stalls. We can see the number of back-end bound operations (i.e. stalled due to waiting on dependencies (slow loads)) is noticeably higher for the Rust SIMD version than for ISPC.

Given the generated SIMD assembly is nearly exactly the same in the Rust code as the Rust-ISPC code the cause of the performance difference is a mystery to me.
Conclusion
When getting to the low level details of a small piece of code, you have a number of options for analysis. cargo asm, perf, and vTune all give you a unique perspective that might be able to tell you where your code could see an improvement.
With only a few lines of code we're able to achieve a near 30% speedup compared to the initial Rust code using either hand rolled SIMD intrinsics or rust-ispc.
Hopefully this gives you some inspiration as to what else might be done if you apply a little ingenuity and SIMD polish to your own work.